
kentoh - Fotolia
Hyper-converged use cases beyond VM stacks: A hardware guide
Explore best hyper-converged appliance and cluster configurations for containers, machine/deep learning, streaming analytics and specific products supporting each of these workloads.

Hyper-converged infrastructure emerged as a convenient way to bundle one or more servers, along with associated storage drives and network interfaces, with a virtualization stack into a high-density, easily deployed appliance. The combination proved to be immensely popular, and as the infrastructure technology matured, the types of hyper-converged use cases expanded well beyond its initial strengths.
Today, the hyper-converged infrastructure market generates $2 billion in sales per quarter, according to IDC, with long-term growth of about 90% annually since 2015. Hyper-converged infrastructure's target enterprise market spans SMBs that like the plug-and-play simplicity and single-vendor accountability, to multinationals drawn to the platform's versatility and the multinode scalability to handle diverse and growing workloads. From its niche as the preferred platform for virtual desktop infrastructure (VDI) and branch office infrastructure, hyper-convergence has ridden rapidly improving performance curves for its key components -- namely CPUs, storage drives (particularly flash) and network interface cards (NICs) -- to become a viable option for most workloads.
While hyper-converged infrastructure started as a virtualization hardware appliance, innovations in software technology have created new use case opportunities suitable for the platform. This includes three key areas in IT significantly changing how organizations understand their growing reservoir of data and how they develop and deploy new applications: container clusters, machine learning and deep learning algorithms, and streaming data analytics.
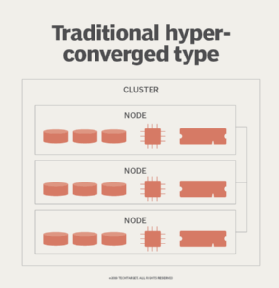
Each of these use cases has somewhat different system requirements than those for the conventional VM server farms hyper-converged infrastructure initially addressed. However, since at their core, hyper-converged hardware boxes are little more than tightly packaged servers with a centralized management console, there's no reason the platform can't evolve to address these new workloads.
The following is an overview of how organizations can use hyper-converged infrastructure for these three environments -- containers, machine/deep learning and streaming data analytics -- that have become increasingly strategic to most businesses and their IT staffs. We include examples of specific hyper-converged hardware products and vendors to help illustrate appliance and cluster configurations that work best for these different use cases.
Containers and hyper-convergence
Container clusters are a natural fit for hyper-converged infrastructure because the hardware requirements are practically the same as those for VM infrastructure. Indeed, many of the leading hyper-convergence vendors like Dell EMC/VMware, Nutanix and Cisco now offer configurations optimized for the popular container software stacks like Kubernetes.
However, these products didn't become market leaders by virtue of their hardware, which is virtually indistinguishable from each other and that of white box OEM hyper-converged hardware products. What sets them apart is their bundled software. Indeed, Nutanix is primarily now a software company that puts hardware from OEM partners on equal footing with its branded hardware.
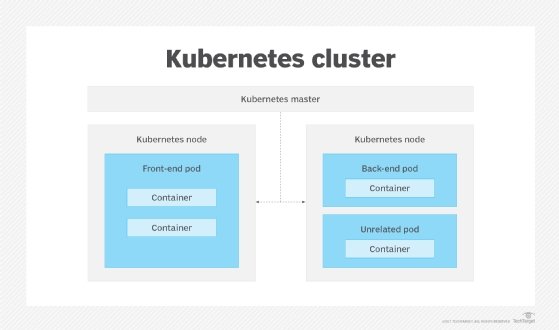
Most hyper-converged infrastructure vendors today have pivoted to container infrastructure, typically by incorporating open source Kubernetes, the de facto standard for cluster and workload management -- with auxiliary storage, virtual networking and management features critical to enterprise deployments. Indeed, since Kubernetes handles node management, workload provisioning and load balancing, virtual networking and storage are the main way hyper-converged hardware vendors can differentiate their products from the open source package.
For example, the Diamanti Container Network Interface (CNI) uses single root I/O virtualization function interfaces on each node for its management software to dynamically assign virtual IPs to new containers when they are scheduled. The platform tracks IP assignments as applications are moved and handles intra-cluster routing.
Robin.io, a relatively new hyper-converged infrastructure vendor specializing in container workloads, uses a similar CNI based on a combination of Open vSwitch and Calico -- a virtual network control plane -- that can create an L3 virtual overlay so clusters and workloads can span data centers or cloud environments. It also provides Pod IPs that persist when moved between hosts or are stopped and restarted.
A key benefit of containers -- the ability to quickly move and scale workloads within a cluster -- presents a problem for the majority of enterprise applications that must access persistent storage. Unlike a VM that can statically mount a volume, using persistent volumes within a Kubernetes cluster requires additional work (as detailed in the Kubernetes documentation). Many hyper-converged infrastructure vendors address this need by incorporating storage and data management features into their container-ready products.
For example, the Robin Storage module integrates with core Kubernetes components to provide features like automatic storage provisioning, snapshots, backup, recovery, replication/cloning and quality of service. It also works with the Robin management software to enable migrating persistent container applications between cloud environments, including public cloud containers as a service products like Google Cloud Google Kubernetes Engine.
Other vendors like Diamanti provide Kubernetes applications with persistent access to low-latency NVMe block storage protected by snapshots and asynchronous mirroring.
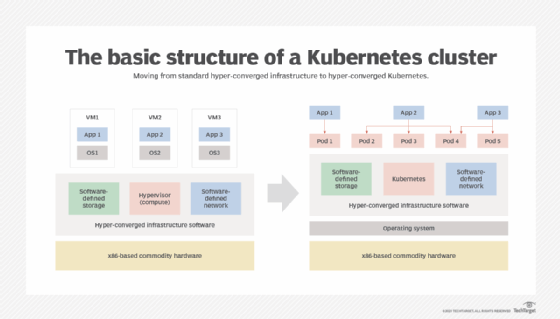
Machine and deep learning
We started with containers on hyper-converged infrastructure because they are the foundation for encapsulating other software like machine/deep learning and data analytics applications. The first and arguably most significant effort at enabling containerized AI applications came via the Nvidia GPU Cloud, which has since been emulated by other cloud platforms including AWS, Google (Deep Learning Containers), RedHat and Azure.
While containers provide the software substrate, traditional hyper-converged products will generally need hardware augmentation to handle most AI workloads, notably for training deep learning models due to their heavy use of matrix math. Although Intel added new features to the second-generation Xeon Scalable processors introduced last year that it claims makes them suitable for training some models (notably for image classification), GPUs remain the fastest and most popular compute engine for AI calculations.
Many hyper-converged vendors have added GPU configurations to their portfolio, including Dell EMC (VxRail E series), NetApp H series and Cisco HyperFlex. These typically link to the host processor over the PCIe bus. However, for large, complex models that require more than one GPU, PCIe latency and memory semantics can limit performance.
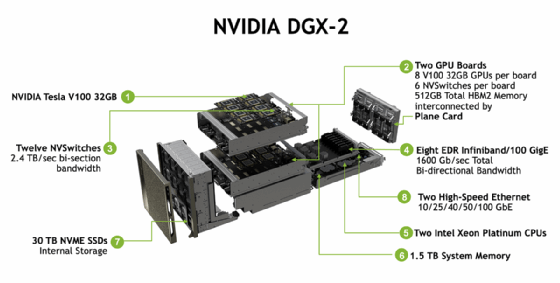
Instead, GPU-intensive applications are better served by specialized hardware using a dedicated high-speed GPU interconnect like NVLink. While systems like the NVIDIA DGX-1, -2 and Pod or the IBM Power System AC922 aren't traditional hyper-converged infrastructure products, they work similarly by aggregating multiple CPU, GPU and storage modules into a single chassis that can be shared among multiple workloads.
Streaming data analytics
The compute needs of streaming data ingestion and analysis are well within the capabilities of conventional hyper-converged systems. Any unique hardware differences result from the size and volume of data being ingested and the location where it must be processed. Users typically place systems handling streaming data close to the source, such as within a retail store for a system ingesting and analyzing video surveillance from multiple cameras, making hyper-converged infrastructure a good fit for streaming use cases due to their density and expandability.
Depending on the volume of data involved, hyper-converged systems for streaming data will need enough drive bays to accommodate incoming data before it is processed and archived. The capacity of current NVMe drives, with 7.68 TB and 15.36 TB storage devices now available, and the density of current systems with 1U chassis containing 10 or 12 bays and 2U having 24 or more bays, are more than adequate for most streaming applications. Indeed, a 1U device with 40 TB to 80 TB of capacity is perfectly capable of handling edge locations, acting as an aggregation point for dozens or hundreds of remote sensors on a manufacturing floor, drilling rig or distribution warehouse.
Streaming analytics systems will also typically run purpose-built software such as Apache Flink that can extract data from conventional databases or systems like ElasticSearch and Apache Kafka. As with AI/machine learning applications, the streaming analytics software can run either as a conventional VM or in containers.
Containers, machine and deep learning, streaming analytics
Enterprises can now turn to hyper-converged infrastructure for any number of use cases, well beyond the integrated and highly scalable IT architecture's initial VDI and remote office/branch office strengths. Container clusters, machine and deep learning, and streaming data analytics are all especially important hyper-converged uses cases for organizations looking to make the most out of the huge -- and exponentially growing -- amounts of data they create, take in and store nowadays.
Selecting a hyper-converged product isn't just about the type of workload you intend to run, however. Don't forget that the system (or systems) you choose and how you end up configuring your hyper-converged hardware and cluster depends on just as much on your specific needs and requirements.




