
What are 3 best practices for decentralized storage systems?
Decentralized storage technology can be confusing and complicated. These best practices, however, can help with implementation in enterprise IT infrastructure.

Decentralization is one of the hottest trends in cloud storage. Rather than storing all of an organization's data in a single location, decentralization breaks the data up into fragments and scatters them across many cloud storage devices.
Decentralized storage systems help insulate data against a cloud data center failure or cyber attack. They also help to keep data private because storage providers do not have a full copy of the data -- only encrypted fragments.
If an organization decides to try decentralized storage, there are three best practices to keep in mind.
1. Choose a reputable provider
One of the top benefits often attributed to decentralized storage systems is that, when properly constructed, there is no single point of failure. In reality, though, the decentralized storage provider is the single point of failure. If this provider goes out of business, then organizations could lose data.
The whole point of decentralized storage is to scatter data across the internet in encrypted fragments. The decentralized storage provider is the only one that knows the location of these fragments and how to put them back together.
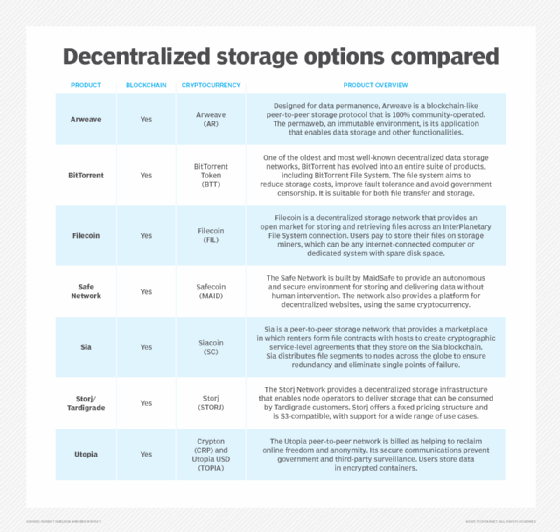
2. Consider the use
Before investing in decentralized storage systems, consider how well the storage is going to work for given workloads. As decentralized storage scatters data across numerous storage devices, there is always going to be latency involved in storage I/O. Organizations may not want to use a decentralized storage system for a high-performance database.
Also, consider how to link workloads to the decentralized storage. Some decentralized storage systems emulate Amazon S3, which makes it relatively easy to connect applications. Other platforms, however, may require organizations to re-factor applications.
3. Gauge the impact
Decentralized storage systems depend on storage redundancy in order to make sure that data remains continuously available. In most cases, data gets uploaded to the decentralized storage provider. The provider then makes multiple copies of the data fragments and sends them to storage repositories around the internet.
However, it's equally possible that a provider might use a system on the user's end to clone the data, which would entail far more upload bandwidth than typical cloud storage.
In addition, consider whether the provider charges data egress fees and how best to create backups of data stored on decentralized storage systems.







