
Artificial intelligence is vital to the future of your organization. Therefore, it is critical to have the right technology platform in place, one designed to meet the very specific data requirements of AI use cases.
The infrastructure required to scale AI from pilot project to production environment is complex. Among other things, the infrastructure must be able to quickly process massive data sets at high speeds and ingest the broadest range of data from structured and unstructured sources.
Deploying AI in a real-world production environment requires an end-to-end pipeline incorporating these pillars:
- Ingest: This stage streams the data from the source into the training system. The data is stored in raw form, and even when labels are added to enrich the data in the next stage, the original raw data is not deleted.
- Clean and transform: At this stage, the data is modified and stored in a format convenient for feature extraction and model exploration, including linking the data sample and associated label. A second copy of the data is not backed up because it can be recomputed if needed. This is usually done on standard CPU servers.
- Exploration: In the exploration phase, data scientists iterate quickly, kicking off single GPU tasks to develop the model and validate their hypothesis. This is a highly iterative process and a critical place where data teams aren’t productive.
- Training: Training phases select batches of input data, including both new and older samples, and feed those into larger-scale production GPU servers for computation, to build an accurate model over large data sets. The end results go into the inferencing application, which then runs on new or live data. Once these processes are completed, you have an AI product that can be put into devices such as cars or phones.
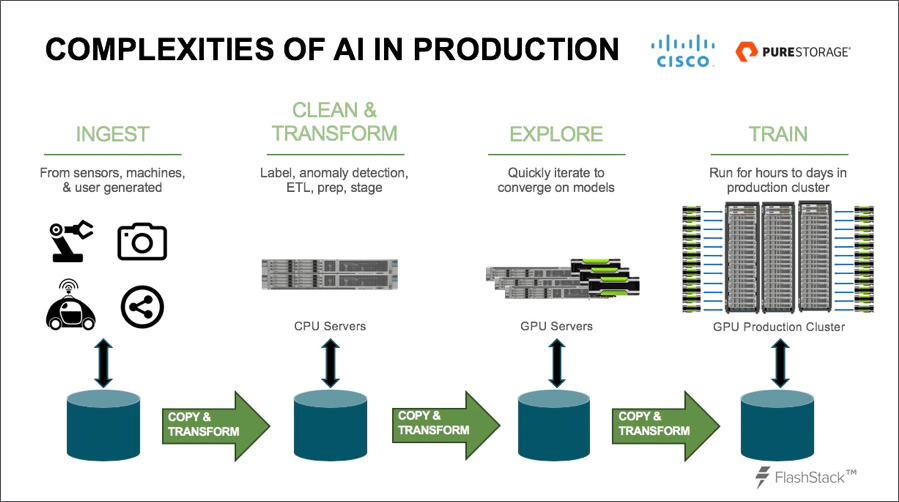
Each of these stages has a different requirement for compute and storage, so many organizations tend to build separate physical silos, whereby data is transformed, then copied, then moved from one stage to the next.
This approach is inefficient, however, because it slows down development and is costly to deploy and manage. Instead of separate silos, organizations need an end-to-end data pipeline solution that can serve as the foundation for any and all AI initiatives.
Introducing a new approach to AI infrastructure
FlashStack for AI is the first holistic solution designed to offer a complete end-to-end AI pipeline. The product is the extension of the longtime collaboration between Cisco and Pure Storage. FlashStack for AI is an integrated solution purpose-built for AI and machine learning use cases. It incorporates leading-edge technologies from Cisco and Pure Storage in a fully converged infrastructure. Critical components are:
- The Cisco UCS C480 ML system: This is a purpose-built rack server for deep learning and machine learning that includes eight NVIDIA Tesla V100 Tensor Core GPUs with an NVLink interconnect for faster model training.
- Cisco Nexus switches: These provide the massive network bandwidth required by AI and ML applications, enabling the data throughput required throughout the pipeline, all the way from storage into the GPU. In addition, Cisco’s Fabric supports flexible multiprotocol for storage interconnect to support fast data ingestion to the high-performance C480 ML servers.
- The Pure Storage FlashBlade data hub: This is an elastic scale-out storage platform that delivers performance that scales linearly as data grows. It has been designed for next-generation analytics and AI workloads, enabling enterprises to seamlessly share data across the modern AI pipeline. FlashBlade is built to unify file and object storage on a single scale-out platform to consolidate all data-intensive applications. It eliminates metadata performance bottlenecks and is designed to be massively parallel.
Accelerate AI Data Pipeline - Flashstack™ for AI
Discover how Flashstack™ for AI can power the data pipeline at every stage and reduce deployment risks while remaining flexible enough to scale-out to meet any increased workloads.
Download NowWith FlashStack for AI, organizations can deploy a validated architecture for AI workloads that reduces the design risks in building a data, compute and storage infrastructure for the AI data pipeline. With FlashStack for AI, IT can simplify building and deploying infrastructure for the entire AI pipeline.
Are you ready to take the next step on the path to maximizing AI value? Please review the articles and resources in this section to begin your journey from AI priority to AI reality.
