
The path to successful real-world deployment of artificial intelligence and machine learning starts with understanding what tasks, processes and applications AI and ML can improve for your organization. Only then can you understand which data and data sets will be required to drive the right outcomes. Moreover, such analysis is necessary to decide how to roll out AI, including whether to target specific pilot projects or deploy AI in multiple areas.
Because of the challenges and complications involved in deploying and scaling AI (link to real-world AI article), most businesses are still targeting AI for specific applications, such as IT automation and cybersecurity. For the record, only 4% of organizations are looking at full enterprise-wide deployment in 2020; 42% are still investigating use, and 54% are deploying AI in multiple areas or pilot projects.
Regardless of how you look at deploying AI, one of the biggest challenges is overcoming the various silos that are endemic to most organizations.
Some of these are technological gaps specific to the data pipeline, with massive volumes of structured and unstructured data, often created in various formats and locked into silos, moving at unprecedented velocities―and all or most of this data needs to be gathered, cleaned and collated before it even gets to the stage of being useful for AI. As if that weren’t challenging enough, as businesses embrace hybrid cloud and multicloud environments, they run the additional risk that data critical to AI modeling and training will be siloed and isolated from those who need it.
Perhaps just as important as managing and modernizing the data pipeline for real-world AI success is the need to overcome personnel-related cultural gaps that can cripple AI initiatives before they get off the ground. These include gaps between ever-evolving personas—all of whom may need to be collaborative participants in AI deployments. This includes IT teams, database administrators, data architects, data scientists, developers, site reliability engineers and even corporate and line-of-business managers.
Closing technology gaps
Decision-makers involved in deploying AI say data integration is the most important challenge associated with the data pipeline, according to Enterprise Strategy Group. This makes sense because having the right data is the foundation for any successful AI initiative.
But it’s not just having the right data. It’s also about closing the gaps in performance between existing IT infrastructures that have not been designed for AI and utilizing a data platform that can handle the myriad technical challenges required to make AI real.
The AI infrastructure must be able to manage every element of the data pipeline, from data ingestion and cleansing to training and inferring results. This requires high-performance engines dedicated to workload compute processing, along with a storage platform designed for massive data throughput, linearly scaling performance and other vital performance, capacity and scaling capabilities necessary for real-world AI.
Accelerate AI Data Pipeline - Flashstack™ for AI
Discover how Flashstack™ for AI can power the data pipeline at every stage and reduce deployment risks while remaining flexible enough to scale-out to meet any increased workloads.
Download NowClosing cultural gaps
Even with the right data pipeline and hub in place, organizations must still address the personnel and cultural gaps that can stifle successful AI deployments. IT and data science teams must understand each other’s requirements and limitations due to myriad issues such as regulation, privacy and security. “Operational silos between roles create constant challenges,” ESG notes, citing the following example:
Data scientists aligned to a specific line of business understand the business use case and data science approach necessary to solve it, while IT will likely lack the data science or business acumen necessary to properly align infrastructure to efficiently and effectively support requirements. If the data scientists need access to new data, integrating new and different data sets may lead to different IT requirements. This is the primary reason for data integration being the most often cited challenge associated with the data pipeline.
That’s just one example of various personas needing to be on the same page. When you look at production-scale AI-powered applications, AI becomes just a part of the entire ecosystem. So, if you are doing deployments through Kubernetes, it requires a collaboration among data scientists, DevOps teams, DBAs, and IT and infrastructure engineers.
Everyone needs to not only be able to work together but also easily share information and understand the various elements on which other collaborative teams are working. The following graphic provides an illustration of the potential challenges involved:
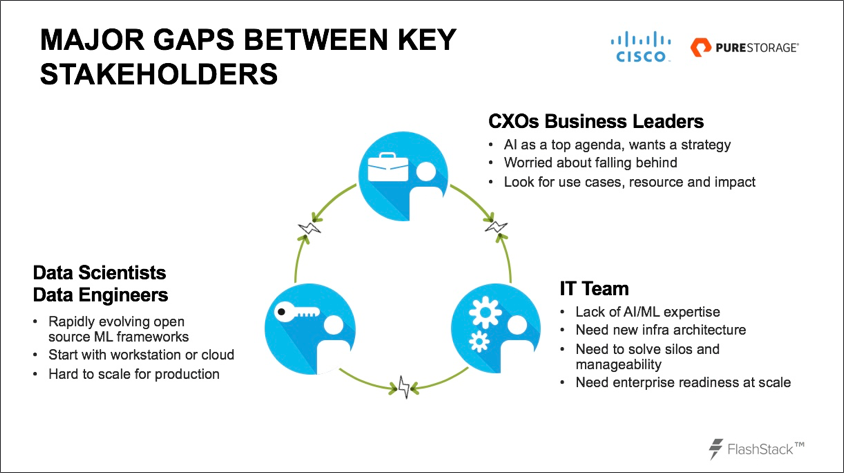
Taking the next step
Being aware that these gaps exist is the first step toward fixing them. It starts with deploying an AI infrastructure platform that makes it easier for teams to collaborate and share data, using a consistent, high-performance, resilient, scalable pipeline.
While different personas may be working on different elements of the IT puzzle, they must ensure that they have all the data they need and can easily access and share it to contribute their part.
How do you find the right infrastructure for your AI pipeline? Start here.
